段首语
此系列文章用来做R语言的学习,以及对于使用R语言进行数据处理和作图的代码汇总,方便大家随时进行查找、使用。
下一篇:R codebase (三) 基础作图与ggplot2
一、数据的导入与输出
1.导入
表格
1
2
3
read_*(file, col_names = TRUE, col_types = NULL, locale = default_locale(), na = c("", "NA"),
quoted_na = TRUE, comment = "", trim_ws = TRUE, skip = 0, n_max = Inf,
guess_max = min(1000, n_max), progress = interactive())
逗号分隔:read_csv(“file.csv”)
分号分隔:read_csv2(“file2.csv”)
任意分隔符:read_delim(“file.txt”, delim = “|”)
任意宽度的空格分隔:read_fwf(“file.fwf”, col_positions = c(1, 3, 5))
tab键分隔:read_tsv(“file.tsv”) or read_table()
=====================================================
参数
去除表头:read_csv(f, col_names = FALSE)
自定义表头:read_csv(f, col_names = c(“x”, “y”, “z”))
跳行:read_csv(f, skip = 1)
选定行:read_csv(f, n_max = 1)
替换值为NA:read_csv(f, na = c(“1”, “.”))
文件
文件读入为一个字符串:read_file(file, locale = default_locale())
文件读入为多行字符串:read_lines(file, skip = 0, n_max = -1L, na = character(), locale = default_locale(), progress = interactive())
文件读入为一个向量:read_file_raw(file)
文件读入为多行向量:read_lines_raw(file, skip = 0, n_max = -1L, progress = interactive())
2.输出
与导入类似:
逗号分隔:write_csv(x, path, na = “NA”, append = FALSE, col_names = !append)
指定分隔:write_delim(x, path, delim = “ “, na = “NA”, append = FALSE, col_names = !append)
Excel:write_excel_csv(x, path, na = “NA”, append = FALSE, col_names = !append)
字符串到文件:write_file(x, path, append = FALSE)
字符串向量到文件,每行一个分隔符:write_lines(x,path, na = “NA”, append = FALSE)
RDS文件:write_rds(x, path, compress = c(“none”, “gz”, “bz2”, “xz”), …)
tab键分隔write_tsv(x, path, na = “NA”, append = FALSE, col_names = !append)
二、数据的扩展、合并、分解(tidyr)
1.数据的重构
- 扩展
gather(data, key, value, …, na.rm = FALSE, convert = FALSE, factor_key = FALSE)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
library(tidyr)
data1 <- data.frame(country = c("A","B","D"),"Y1999" = c("2.7K","3.8K","1.4K"),"Y2000" = c("3.0K","4.5K","2.0K"))
data1
## country Y1999 Y2000
## 1 A 2.7K 3.0K
## 2 B 3.8K 4.5K
## 3 D 1.4K 2.0K
gather(data1, "Y1999", "Y2000", key = "year", value = "cases")
## country year cases
## 1 A Y1999 2.7K
## 2 B Y1999 3.8K
## 3 D Y1999 1.4K
## 4 A Y2000 3.0K
## 5 B Y2000 4.5K
## 6 D Y2000 2.0K
- 合并
spread(data, key, value, fill = NA, convert = FALSE, drop = TRUE, sep = NULL)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
library(tidyr)
data2 <- data.frame(country = rep(c("A","B","C"),each=4),
year = rep(rep(c("Y1999","Y2000"),each=2),times=3),
type = rep(c("cases","pop"),times=6),
count = c("2.7K","2.6K","5.6K","3.5K","3.7K","1.7K","3.9K","2.4K","2.9K","2.0K","2.1K","4.6K")
)
data2
## country year type count
## 1 A Y1999 cases 2.7K
## 2 A Y1999 pop 2.6K
## 3 A Y2000 cases 5.6K
## 4 A Y2000 pop 3.5K
## 5 B Y1999 cases 3.7K
## 6 B Y1999 pop 1.7K
## 7 B Y2000 cases 3.9K
## 8 B Y2000 pop 2.4K
## 9 C Y1999 cases 2.9K
## 10 C Y1999 pop 2.0K
## 11 C Y2000 cases 2.1K
## 12 C Y2000 pop 4.6K
spread(data2, type, count)
## country year cases pop
## 1 A Y1999 2.7K 2.6K
## 2 A Y2000 5.6K 3.5K
## 3 B Y1999 3.7K 1.7K
## 4 B Y2000 3.9K 2.4K
## 5 C Y1999 2.9K 2.0K
## 6 C Y2000 2.1K 4.6K
2.对于na值的处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
x <- data.frame(x1 = LETTERS[seq(1,5)],
x2 = c(1,NA,NA,3,NA))
x
## x1 x2
## 1 A 1
## 2 B NA
## 3 C NA
## 4 D 3
## 5 E NA
## 去除 drop_na(data, ...)
drop_na(x, x2)
## x1 x2
## 1 A 1
## 2 D 3
## 填充 fill(data, ..., .direction = c("down", "up"))
fill(x, x2)
## x1 x2
## 1 A 1
## 2 B 1
## 3 C 1
## 4 D 3
## 5 E 3
## 替换 replace_na(data, replace = list(), ...)
replace_na(x, list(x2 = 2))
## x1 x2
## 1 A 1
## 2 B 2
## 3 C 2
## 4 D 3
## 5 E 2
3.填充和完善
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
head(mtcars)
## mpg cyl disp hp drat wt qsec
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02
## Valiant 18.1 6 225 105 2.76 3.460 20.22
## vs am gear carb
## Mazda RX4 0 1 4 4
## Mazda RX4 Wag 0 1 4 4
## Datsun 710 1 1 4 1
## Hornet 4 Drive 1 0 3 1
## Hornet Sportabout 0 0 3 2
## Valiant 1 0 3 1
## complete(data, ..., fill = list())
complete(mtcars, cyl, gear, carb)
## # A tibble: 74 × 11
## cyl gear carb mpg disp hp drat wt
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 4 3 1 21.5 120. 97 3.7 2.46
## 2 4 3 2 NA NA NA NA NA
## 3 4 3 3 NA NA NA NA NA
## 4 4 3 4 NA NA NA NA NA
## 5 4 3 6 NA NA NA NA NA
## 6 4 3 8 NA NA NA NA NA
## 7 4 4 1 22.8 108 93 3.85 2.32
## 8 4 4 1 32.4 78.7 66 4.08 2.2
## 9 4 4 1 33.9 71.1 65 4.22 1.84
## 10 4 4 1 27.3 79 66 4.08 1.94
## # … with 64 more rows, and 3 more variables:
## # qsec <dbl>, vs <dbl>, am <dbl>
## expand(data, ...)
expand(mtcars, cyl, gear, carb)
## # A tibble: 54 × 3
## cyl gear carb
## <dbl> <dbl> <dbl>
## 1 4 3 1
## 2 4 3 2
## 3 4 3 3
## 4 4 3 4
## 5 4 3 6
## 6 4 3 8
## 7 4 4 1
## 8 4 4 2
## 9 4 4 3
## 10 4 4 4
## # … with 44 more rows
4.单元格的分解与合并
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
datax <- data.frame(country = rep(c("A","B","C"),each = 2),
year = rep(c("Y1999","Y2000"),times = 3),
rate = c("0.7K/19M","2K/20M","37K/172M","80K/174M","212K/1T","213K/1T"))
datax
## country year rate
## 1 A Y1999 0.7K/19M
## 2 A Y2000 2K/20M
## 3 B Y1999 37K/172M
## 4 B Y2000 80K/174M
## 5 C Y1999 212K/1T
## 6 C Y2000 213K/1T
#### 分解为多列
## separate(data, col, into, sep = "[^[:alnum:]] +", remove = TRUE, convert = FALSE, extra = "warn", fill = "warn", ...)
separate(datax, rate, sep = "/",into = c("cases", "pop"))
## country year cases pop
## 1 A Y1999 0.7K 19M
## 2 A Y2000 2K 20M
## 3 B Y1999 37K 172M
## 4 B Y2000 80K 174M
## 5 C Y1999 212K 1T
## 6 C Y2000 213K 1T
#### 分解为多行
## separate_rows(data, ..., sep = "[^[:alnum:].]+", convert = FALSE)
separate_rows(datax, rate)
## # A tibble: 12 × 3
## country year rate
## <chr> <chr> <chr>
## 1 A Y1999 0.7K
## 2 A Y1999 19M
## 3 A Y2000 2K
## 4 A Y2000 20M
## 5 B Y1999 37K
## 6 B Y1999 172M
## 7 B Y2000 80K
## 8 B Y2000 174M
## 9 C Y1999 212K
## 10 C Y1999 1T
## 11 C Y2000 213K
## 12 C Y2000 1T
#### 合并
## unite(data, col, ..., sep = "_", remove = TRUE)
unite(datax, country, year, col = "c_y", sep = "")
## c_y rate
## 1 AY1999 0.7K/19M
## 2 AY2000 2K/20M
## 3 BY1999 37K/172M
## 4 BY2000 80K/174M
## 5 CY1999 212K/1T
## 6 CY2000 213K/1T
三、数据的形式转换(dplyr)
![]()
![]()
四、数据的形式转换(data.table)


五、数据的形式转换(sjmisc)

六、apply的使用(purr)
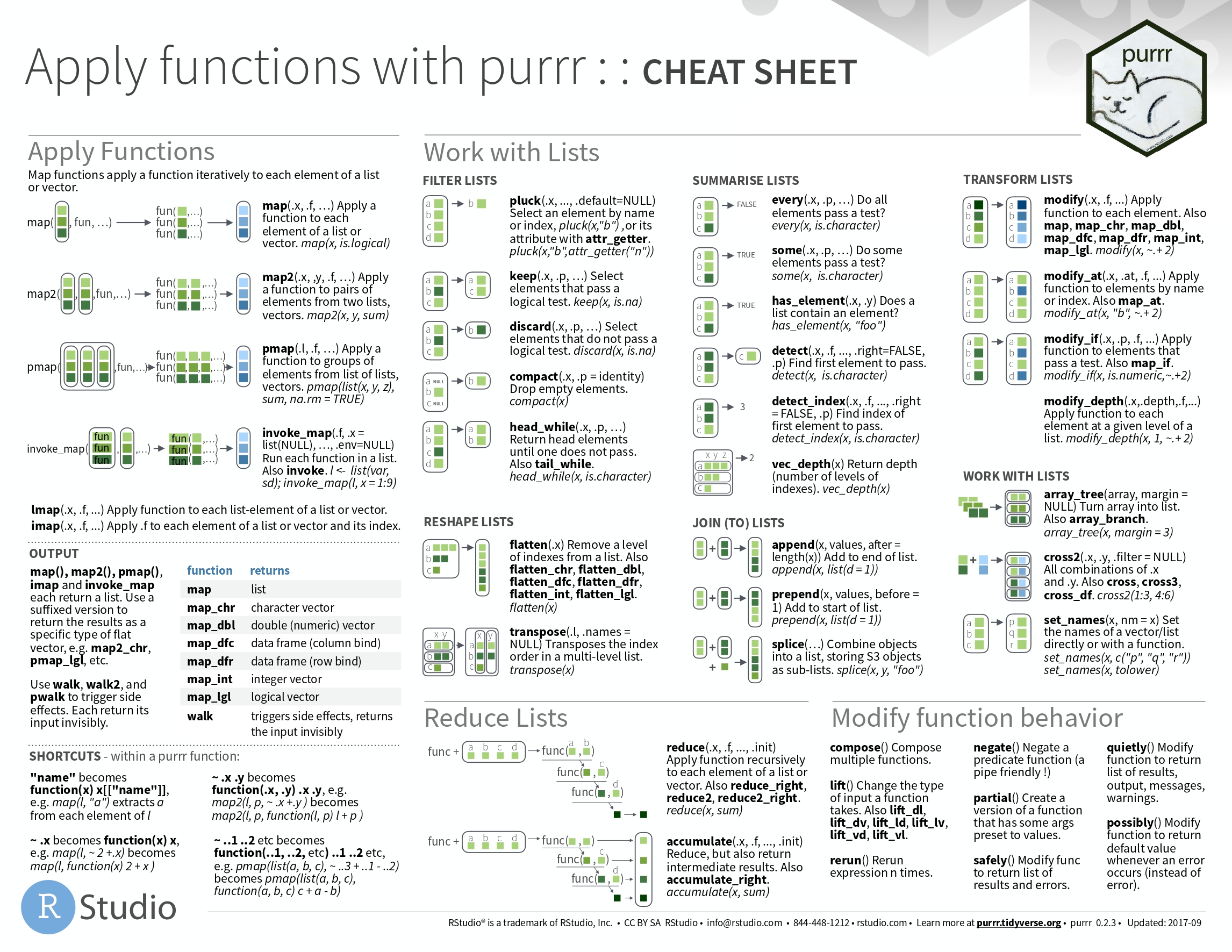

七、String类的修改
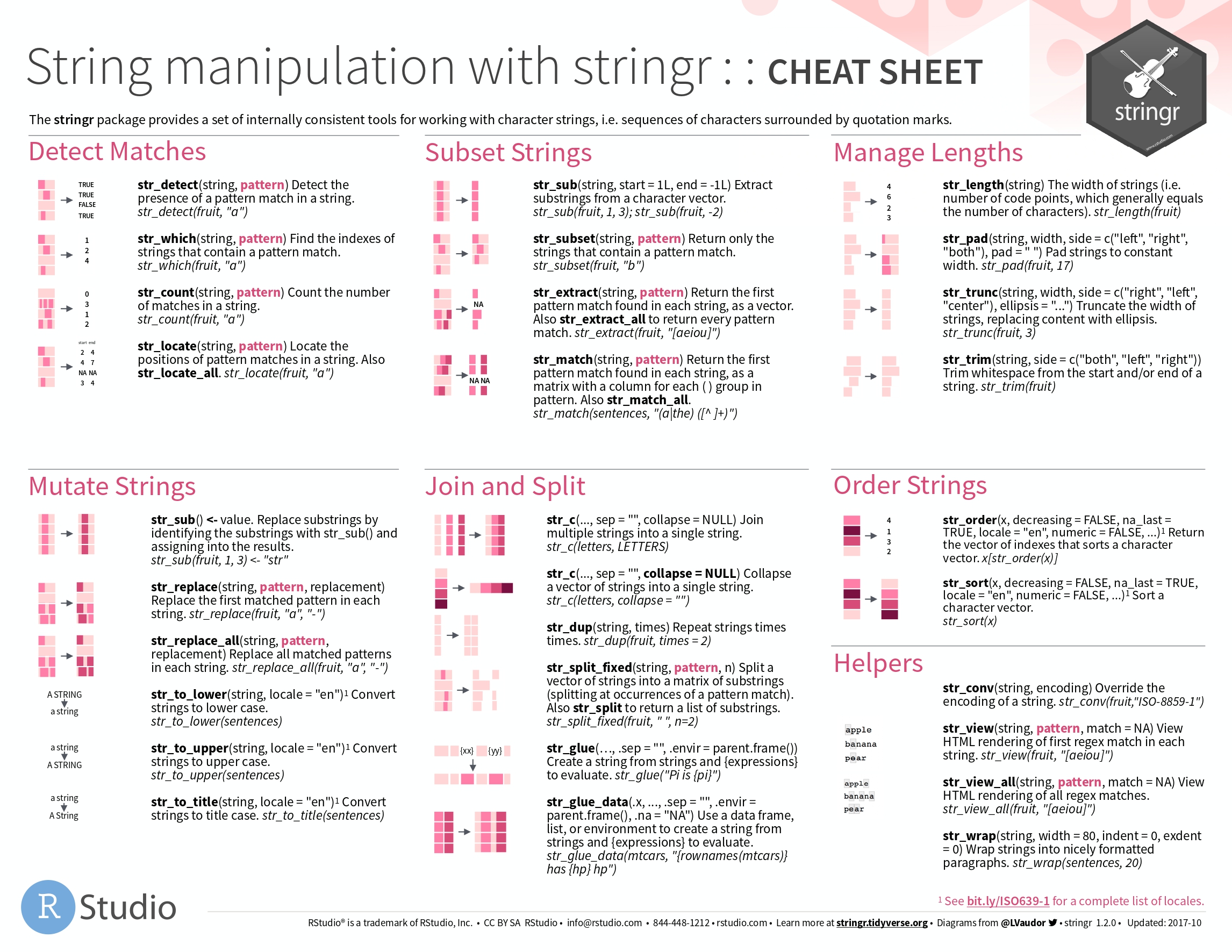

cheatsheet 引用自 https://github.com/FavioVazquez/ds-cheatsheets
持续更新 。。。
